The 5-year journey to bring restartable sequences to Linux
The EfficiOS team on 08 February 2019
Concurrency control algorithms, paired with per-CPU data, are integral to ensuring low-level libraries and high-performance applications scale properly on today's hardware. These algorithms guarantee that user-space data structures are kept consistent in the face of simultaneous accesses, and that modifications are done wholly so that threads see either the before or after state, but not in between.
There are a number of ways to design these algorithms. The most common, though least scalable, is with mutual exclusion which works by allowing only one thread to modify the data structure at any one time — and that's the thread holding the mutex.
But mutual exclusion doesn't scale well, particularly with per-CPU data. Since only one thread can be within the critical section bookended by the mutex lock and unlock sequence, it's possible to have many threads waiting to acquire the lock. And time waiting for locks is time not spent doing useful work.
The next step up on the list of scalable algorithms is atomic compare and swap.
In this model, a single instruction is used such as cmpxchg or
the lock prefix in the case of x86.
The problem here though is that atomic instructions are relatively expensive on
modern processors. The x86 lock prefix can easily add many cycles to the cost
of the same instruction without the prefix. To make matters worse, regardless
of whether there's only one thread executing the instruction or not the lock
prefix will be executed.
And not all architectures provide a single instruction for atomically updating data. For instance, ARM uses link-load/store-conditional instructions to read the old data, modify it, and write the new data. If two threads try to write the same data simultaneously only one will succeed and the other will fail and restart the read-modify-write sequence.
The Linux kernel uses other methods of protecting per-CPU data, such as disabling preemption or interrupts, or using “percpu” local atomic operations. Unfortunately, these mechanisms are either not readily available to user-space, or they're comparatively slow (as is the case with the atomic instructions). Instead, what's needed is a lightweight mechanism for user-space to protect per-CPU data. This is the motivation for restartable sequences.
How Restartable Sequences Work
Restartable sequences are built with a new system call, rseq(2),
that tells the kernel where the restartable sequence's thread-local storage
ABI (a struct rseq object) is located for the
current thread. This object contains a rseq_cs field which is a
pointer to the currently active restartable sequence critical section
descriptor (a struct rseq_cs object). Only one critical section
can be active at any time. This ABI has two purposes: user-space restartable
sequences and a way to quickly read the current CPU number.
The critical section is subdivided into preparatory and commit stages, where the commit step is a single CPU instruction. The critical section is said to have been interrupted if any of the following occur before the commit step:
- The thread is migrated to another CPU
- A signal is delivered to the thread
- The thread is preempted
Additionally, because a fallback mechanism is required when the thread is interrupted, the kernel sets the instruction pointer to the start of an abort handler which can take some corrective action, for example retrying the preparatory step.
With this design, the optimistic case (where the thread isn't interrupted) is extremely fast because expensive locks and atomic instructions can be entirely avoided.
Getting down into the details, the current restartable sequence critical
section is described by a struct rseq_cs object which is
referenced by a struct rseq object. Here's a diagram to illustrate
the relationship and the structure members.
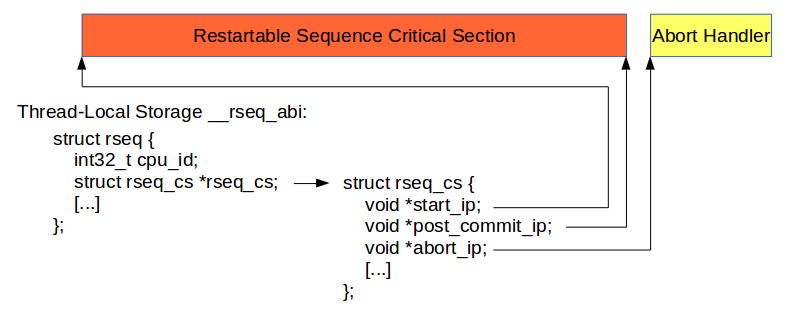
The start and end of the restartable sequence are denoted by the
start_ip and post_commit_ip (which points to the
instruction after the commit instruction), and the abort_ip points
to the first instruction of the abort handler.
There are restrictions on the implementation of both the critical section and the abort handler. For one, the abort handler must be outside the critical section. Secondly, system calls are not permitted within a critical section, and attempting to execute a system call will cause the process to be terminated via a segmentation fault.
The cpu_id field is updated by the kernel whenever a thread
migrates to a new CPU and user-space programs are expected to read
cpu_id_start at the beginning of the critical section and compare
the two values. If they differ then the running thread was interrupted and the
restartable sequence needs to be retried.
The rseq_cs field is modified by both the kernel and user-space.
When beginning a restartable sequence, user-space code needs to set the pointer
to the current critical section descriptor. The kernel sets this pointer to
NULL whenever it preempts or delivers a signal while executing a region of code
that lays outside of the critical section range described by the current
rseq_cs descriptor.
A Brief History of rseq
Support for restartable sequences was merged in Linux 4.18. The concept of restartable sequences, or rseq, was originally proposed by Paul Turner and Andrew Hunter in 2013 as a way to safely access per-CPU data from user-space data without locks or expensive atomic instructions. But at the time no patches were available.
After two years — and in an effort to cajole them into posting their patches to the Linux kernel mailing list — Mathieu Desnoyers submitted his own patches for per-CPU critical sections in May 2015. A month later, the very first patch series for restartable sequences was posted by Paul. After momentum died down on Paul's version, Mathieu picked it up in 2016 and submitted a new series and covered them in a talk at Linux Plumbers Conference 2016. He had hoped to get the patches merged for version 4.15 of the Linux kernel but there was a snag…
While benchmark data was available with pretty much every version of the patch series, Linus made it clear that hypothetical use cases were not reason enough to merge the restartable sequences feature, and that concrete performance numbers were necessary.
Facebook had already provided results for using the patches with the jemalloc memory allocator. So, Mathieu set about collecting more benchmark results and getting rseq support ready for other projects such as LTTng-UST, Userspace RCU, and glibc.
Finally, after five years the series was merged into the Linux kernel, and Mathieu gave a talk at the Open Source Summit Europe 2018 entitled Improve Linux User-Space Core Libraries with Restartable Sequences which covered the multi-year effort of bringing restartable sequences to Linux.
How to Use rseq in your Library or Application
The preferred approach to using restartable sequences is to use the
librseq library which provides all the
per-CPU operations you're likely to need such as making rseq(2)
available to the current thread (rseq_register_current_thread()),
looking up the CPU number of the current thread
(rseq_current_cpu()), and updating per-CPU data
(rseq_cmpeqv_storev()).
But if you want to roll your own operations, read on for a more detailed explanation.
Using rseq(2) requires two steps. First, you need to enable the
functionality for the current thread with the rseq(2) system call.
The system call has the following prototype:
sys_rseq(struct rseq *rseq, uint32_t rseq_len, int flags, uint32_t sig)
The purpose of the system call is to register a struct rseq object with the
kernel. The flags argument is 0 for registration and RSEQ_FLAG_UNREGISTER for
unregistration. The sig argument is a signature that can be used to validate
the rseq context, in other words the signature used for registration must be
the same one used for unregistration.
Let's assume you want to increment a per-CPU counter using
rseq(2). To do that, you need to get the CPU number of the current
thread (stored in the cpu_id_start field of struct
rseq) and modify the per-CPU counter using a restartable sequence. This
is done with a mixture of C and assembly. Here's the code to do that.
#define _GNU_SOURCE
#include <linux/rseq.h>
#include <stdio.h>
#include <stdlib.h>
#include <syscall.h>
#include <stdint.h>
#include <unistd.h>
#include <sys/syscall.h>
static __thread volatile struct rseq __rseq_abi;
#define RSEQ_SIG 0x53053053
static int sys_rseq(volatile struct rseq *rseq_abi, uint32_t rseq_len,
int flags, uint32_t sig)
{
return syscall(__NR_rseq, rseq_abi, rseq_len, flags, sig);
}
static void register_thread(void)
{
int rc;
rc = sys_rseq(&__rseq_abi, sizeof(struct rseq), 0, RSEQ_SIG);
if (rc) {
fprintf(stderr, "Failed to register rseq\n");
exit(1);
}
}
#define RSEQ_ACCESS_ONCE(x) (*(__volatile__ __typeof__(x) *)&(x))
static int rseq_addv(intptr_t *v, intptr_t count, int cpu)
{
__asm__ __volatile__ goto (
".pushsection __rseq_cs, \"aw\"\n\t"
".balign 32\n\t"
"1:\n\t"
".long 0, 0\n\t"
/* start_ip, post_commit_offset, abort_ip */
".quad 2f, (3f-2f), 4f\n\t"
".popsection\n\t"
".pushsection __rseq_cs_ptr_array, \"aw\"\n\t"
".quad 1b\n\t"
".popsection\n\t"
"2:\n\t"
"leaq 1b(%%rip), %%rax\n\t"
"movq %%rax, %[rseq_cs]\n\t"
"cmpl %[cpu_id], %[current_cpu_id]\n\t"
"jnz 4f\n\t"
"addq %[count], %[v]\n\t" /* final store */
"3:\n\t"
".pushsection __rseq_failure, \"ax\"\n\t"
/* Disassembler-friendly signature: ud1 <sig>(%rip),%edi. */
".byte 0x0f, 0xb9, 0x3d\n\t"
".long 0x53053053\n\t" /* RSEQ_SIG */
"4:\n\t"
"jmp %l[abort]\n\t"
".popsection\n\t"
: /* gcc asm goto does not allow outputs */
: [cpu_id] "r" (cpu),
[current_cpu_id] "m" (__rseq_abi.cpu_id),
[rseq_cs] "m" (__rseq_abi.rseq_cs),
/* final store input */
[v] "m" (*v),
[count] "er" (count)
: "memory", "cc", "rax"
: abort
);
return 0;
abort:
return -1;
}
int main(int argc, char **argv)
{
int cpu, ret;
intptr_t *cpu_data;
long nr_cpus = sysconf(_SC_NPROCESSORS_ONLN);
cpu_data = calloc(nr_cpus, sizeof(*cpu_data));
if (!cpu_data) {
perror("calloc");
exit(EXIT_FAILURE);
}
register_thread();
cpu = RSEQ_ACCESS_ONCE(__rseq_abi.cpu_id_start);
ret = rseq_addv(&cpu_data[cpu], 1, cpu);
if (ret)
fprintf(stderr, "Failed to increment per-cpu counter\n");
else
printf("cpu_data[%d] == %ld\n", cpu, cpu_data[cpu]);
return 0;
}
The code in rseq_addv() begins by filling out a struct rseq_cs object that describes the
segment of the restartable sequence denoted by the start symbol 2, the
post-commit offset (3 - 2), and the abort handler 4. If the thread does not
complete the sequence between labels 2 and 3, control jumps to the 4 label
and then to the abort label in C.
A word of caution: you must ensure that the CPU number is only read once.
Compilers need to be coerced into guaranteeing that with the volatile keyword.
The RSEQ_ACCESS_ONCE() macro above guarantees this.
Exactly How Much Faster is rseq?
One of the main use cases for restartable sequence is getting the CPU number
that the current thread is executing on — usually to then be used as an index
into a per-CPU data structure. The existing method of using sched_getcpu() to
discover the CPU number requires a system call on ARM and invokes the VDSO on
x86. But rseq(2) allows you to read a cached CPU number value in the struct
rseq object shared between kernel and user-space.
The rseq approach results in a 20x speedup on x86 and 35x speedup on ARM.
Here's a graph demonstrating the relative speed improvements of the alternative methods of getting the CPU number for the current thread. In all the following graphs, smaller values are better and reflect a speed increase.
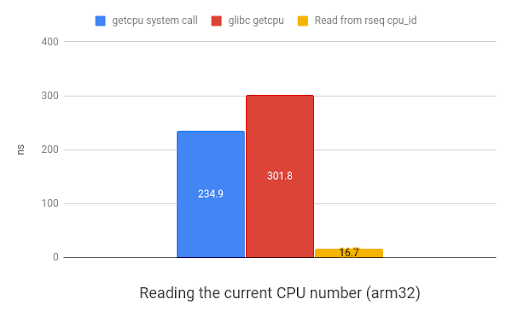
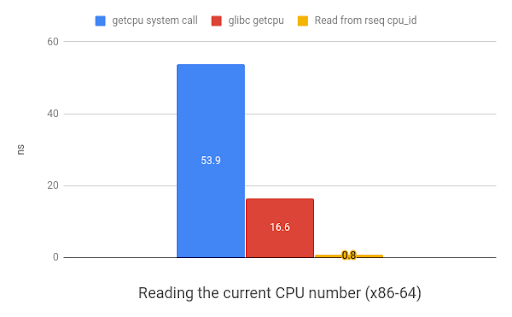
As discussed above, there are a number of use-cases that rseq is suitable for.
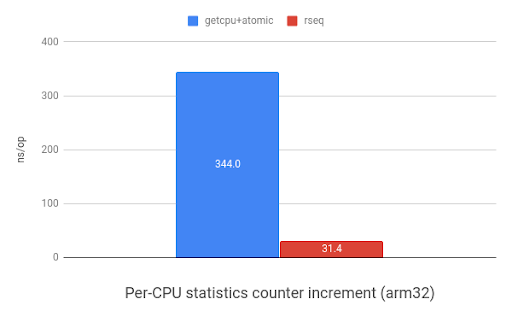
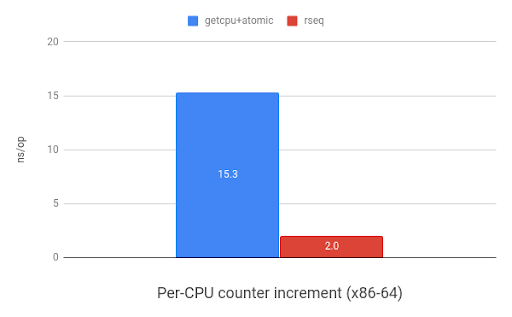
One of the most common uses of per-CPU data is for storing counters. The
following graph shows the speed improvements when incrementing a per-CPU
counter with rseq(2) versus using sched_getcpu() and
atomic instructions. ARM shows an 11x speedup and x86 shows 7.7x.
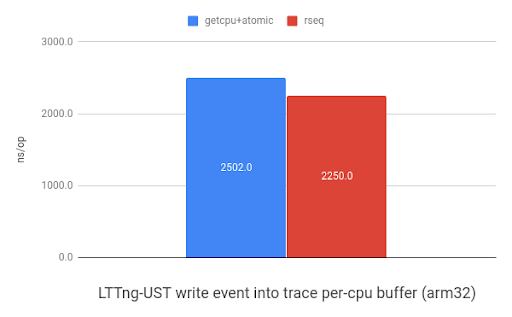
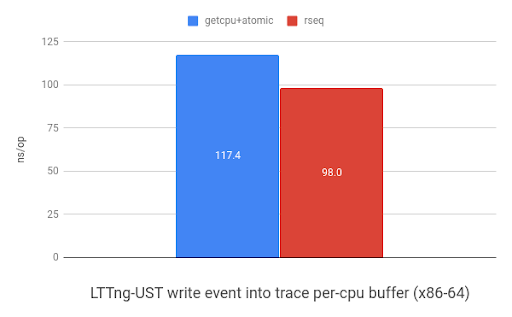
LTTng-UST uses per-CPU buffers to store events. The graph below shows the
performance improvement when storing 32-bit header and 32-bit event payload
into a per-CPU buffer using sched_getcpu() and atomic
instructions or rseq. ARM received a 1.1x speedup and x86 saw a 1.2x improvement.
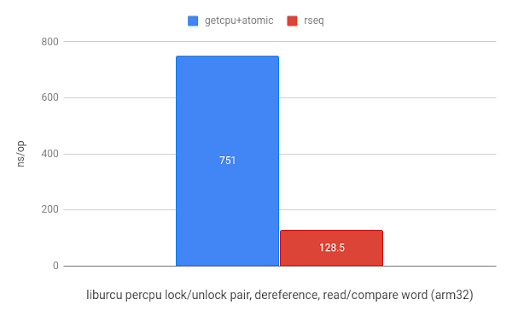
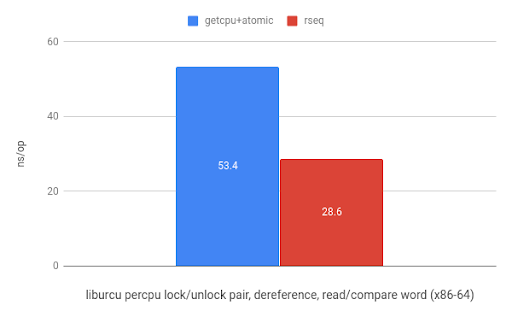
And finally, using rseq in liburcu from the Userspace RCU project results in a 5.8x speedup on ARM and a 1.9x speedup on x86.
What's Next?
While patches to use rseq(2) exist for LTTng, Userspace RCU, and
glibc, however they're only at the proof of concept stage. The next phase is to get
them merged into their respective projects. For glibc, that means patches to
automatically register with rseq(2) at thread start time,
unregister on thread exit, and at NPTL initialization for the main thread.
LTTng-UST is in a slightly different situation because of a shortcoming with
the current design: it's not possible to move data between per-CPU data
structures without also needing to change the thread's affinity mask. To solve
this problem Mathieu has proposed a new cpu_opv system
call
that executes a vector of fixed operations (comparison, memcpy, and add) on a
specific CPU, similar to the struct iovec concept with readv(2) and
writev(2). Another issue with rseq(2) that is solved with cpu_opv is that if
you single-step through a critical section the debugger will loop forever. The
new cpu_opv system call will allow debuggers to work with existing applications
even if libraries make use of rseq(2).
Mathieu had originally hoped to get the new cpu_opv system call merged in time
for the Linux kernel 4.21 release, but Linus Torvalds has made it clear that he
wants to see users of
rseq(2)
implemented first. Meaning those work in progress rseq(2)
patches for glibc need to be merged.
If you want to use rseq(2) in your application or library, we'd love to know
about it. You can contact Mathieu at mathieu.desnoyers@efficios.com.